
При добавлении/изменении большого количества записей (10³ и выше), производительность Entity Framework оставляет желать лучшего. Причиной этому являются как архитектурные особенности самого фреймворка, так и неоптимальный генерируемый SQL. Забегая вперед — сохранение данных в обход контекста сокращает время выполнения на порядки.
Содержание статьи:
1. Insert/Update стандартными средствами Entity Framework
2. Поиск решения проблемы
3. Интеграция Entity Framework и SqlBulkCopy
4. Продвинутая вставка с использованием MERGE
5. Сравнение производительности
6. Выводы
1. Insert/Update стандартными средствами Entity Framework
Начнем с Insert. Стандартным способом добавления новых записей в БД является добавление в контекст с последующим сохранением:
Каждый вызов метода Add приводит к дорогостоящему в плане выполнения вызову внутреннего алгоритма DetectChanges. Данный алгоритм сканирует все сущности в контексте и сравнивает текущее значение каждого свойства с исходным значением, хранимым в контексте, обновляет связи между сущностями и т. п. Известным способом поднятия производительности, актуальным до выхода EF 6, является отключение DetectChanges на время добавления сущностей в контекст:
Также рекомендуется не держать в контексте десятки тысяч объектов и сохранять данные блоками, сохраняя контекст и создавая новый каждые N объектов, например, как тут. Наконец, в EF 6 появился оптимизированный метод AddRange, поднимающий производительность до уровня связки Add+AutoDetectChangesEnabled:
К сожалению, перечисленные подходы не решают основной проблемы, а именно: при сохранении данных в БД, на каждую новую запись генерируется отдельный INSERT запрос!
С Update ситуация аналогичная. Следующий код:
приведет к выполнению отдельного SQL-запроса на каждый измененный объект:
В простейших случаях, может помочь EntityFramework. Extended:
Данный код выполнится в обход контекста и сгенерирует 1 SQL-запрос. Более подробно о скорости EF и работе с этой библиотекой в статье за авторством tp7. Очевидно, что решение не универсальное и годится только для записи во все целевые строки одного и того же значения.
2. Поиск решения проблемы
Испытывая стойкое отвращение к написанию «велосипедов», я в первую очередь поискал best-practices для множественной вставки с помощью EF. Казалось бы, типовая задача — но подходящего решения «из коробки» найти не удалось. В то же время, SQL Server предлагает ряд техник быстрой вставки данных, таких как утилита bcp и класс SqlBulkCopy. О последнем и пойдет речь ниже.
EntityFramework. BulkInsert
На поверку оказавшийся нерабочим. При изучении Issues я наткнулся на дискуссию с участием… небезызвестной Julie Lerman, описывающую проблему, аналогичную моей и оставшуюся без ответа авторов проекта.
EntityFramework. Utilities
Живой проект, активное сообщество. Нет поддержки Database First, но обещают добавить.
3. Интеграция Entity Framework и SqlBulkCopy
Попробуем сделать всё сами. В простейшем случае, вставка данных из коллекции объектов с помощью SqlBulkCopy выглядит следующим образом:
Сама по себе задача реализовать IDataReader на основе коллекции объектов тривиальна, поэтому я ограничусь ссылкой и перейду к описанию способов обработки ошибок при вставке с использованием SqlBulkCopy. По умолчанию, вставка данных производится в своей собственной транзакции. При возникновении исключения выбрасывается SqlException и происходит rollback, т. е. данные в БД не будут записаны вообще. А «родные» сообщения об ошибках данного класса иначе как неинформативными не назовешь. Например, что может содержать SqlException. AdditionalInformation:
К сожалению, SqlBulkCopy зачастую не предоставляет информацию, позволяющую однозначно определить строку/сущность, вызвавшие ошибку. Еще одна неприятная особенность — при попытке вставить дубликат записи по первичному ключу, SqlBulkCopy выбросит исключение и завершит работу, не предоставляя возможности обработать ситуацию и продолжить выполнение.
Маппинг
В случае корректно сгенерированных сущностей и БД становятся неактуальными проверки на соответствие типов, или длину поля в таблице, как тут. Полезней разобраться с маппингом колонок, выполняемым через свойство SqlBulkCopy. ColumnMappings:
Что дает возможность вручную провести маппинг между классом-источником и целевой таблицей.
Использование свойства SqlBulkCopy. BatchSize и класса SqlBulkCopyOptions
SqlBulkCopy. BatchSize:
| BatchSize | Количество строк в каждом пакете. В конце каждого пакета серверу отправляется количество содержащихся в нем строк. |
SqlBulkCopyOptions — перечисление:
| Имя члена | Описание |
|---|---|
| CheckConstraints | Проверять ограничения при вставке данных. По умолчанию ограничения не проверяются. |
| Default | Использовать значения по умолчанию для всех параметров. |
| FireTriggers | Когда задана эта установка, сервер вызывает триггеры вставки для строк, вставляемых в базу данных. |
| KeepIdentity | Сохранять идентификационные значения источника. Когда эта установка не задана, идентификационные значения присваиваются таблицей назначения. |
| KeepNulls | Сохранять значения NULL в таблице назначения независимо от параметров значений по умолчанию. Когда эта установка не задана, значения null, где возможно, заменяются значениями по умолчанию. |
| TableLock | Получать блокировку массового обновления на все время выполнения операции массового копирования данных. Когда эта установка не задана, используется блокировка строк. |
| UseInternalTransaction | Когда эта установка задана, каждая операция массового копирования данных выполняется в транзакции. Если задать эту установку и предоставить конструктору объект SqlTransaction, будет выброшено исключение ArgumentException. |
Мы можем опционально включить проверку триггеров и ограничений на стороне БД (по умолчанию выключена). При указании BatchSize и UseInternalTransaction, данные будут отправляться на сервер блоками в отдельных транзакциях. Таким образом, все успешные блоки до первого ошибочного, будут сохранены в БД.
4. Продвинутая вставка с использованием MERGE
Временная таблица
Необходимо создать таблицу в БД, полностью повторяющую схему таблицы для вставки данных. Создавать копии вручную — худший вариант из возможных, так как вся дальнейшая работа по сравнению и синхронизации схем таблиц также ляжет на ваши плечи. Надежнее копировать схему программно и непосредственно перед вставкой. Например, с использованием SQL Server Management Objects (SMO):
Стоит обратить внимание на класс ScriptingOptions, содержащий несколько десятков параметров для тонкой настройки генерируемого SQL. Полученный StringCollection развернем в String. К сожалению, лучшего решения, чем заменить в скрипте имя исходной таблицы на имя временной а-ля String. Replace(«Order», «Order_TEMP»), я не нашел. Буду благодарен за подсказку красивого решения по созданию копии таблицы в пределах одной БД. Выполним готовый скрипт любым удобным способом. Копия таблицы создана!
Другой вариант — использовать Database. ExecuteWithResults.
Копирование данных из временной таблицы в целевую
Осталось выполнить на стороне SQL Server инструкцию MERGE, сравнивающую содержимое временной и целевой таблиц и выполняющую апдейт или вставку (если необходимо). К примеру, для таблицы [Order] код может выглядеть следующим образом: 
Данный SQL-запрос сравнивает записи из временной таблицы [Order_TEMP] с записями из целевой таблицы [Order], и выполняет Update, если найдена запись с аналогичным значением в поле Id, либо Insert, если такой записи не найдено. Выполним код любым удобным способом, и готово! Не забываем очистить/удалить временную таблицу по вкусу.
5. Сравнение производительности
Среда выполнения: Visual Studio 2013, Entity Framework 6.1.1 (Database First), SQL Server 2012. Для тестирования использовалась таблица [Order] (схема таблицы приведена выше). Были проведены измерения времени выполнения для рассматриваемых в статье подходов к сохранению данных в БД, результаты представлены в ниже (время указано в секундах):
Insert
| Способ фиксации изменений в базе данных | Количество записей | ||
|---|---|---|---|
| 1000 | 10000 | 100000 | |
| Add + SaveChanges | 7,3 | 101 | 6344 |
| Add + (AutoDetectChangesEnabled=false) + SaveChanges | 6,5 | 64 | 801 |
| Add + отдельный контекст + SaveChanges | 8,4 | 77 | 953 |
| AddRange + SaveChanges | 7,2 | 64 | 711 |
| SqlBulkCopy | 0,01 | 0,07 | 0,42 |
Ого! Если использовать метод Add для добавления в контекст и SaveChanges для сохранения, сохранение 100000 записей в БД займет почти 2 часа! В то время, как SqlBulkCopy на эту же задачу тратит менее секунды!
Update
| Способ фиксации изменений в базе данных | Количество записей | ||
|---|---|---|---|
| 1000 | 10000 | 100000 | |
| SaveChanges | 6,2 | 60 | 590 |
| SqlBulkCopy + MERGE | 0,04 | 0,2 | 1,5 |
Вновь SqlBulkCopy вне конкуренции. Исходный код тестового приложения доступен на GitHub.
Выводы
В случае работы с контекстом, содержащим большое количество объектов (10³ и выше), отказ от инфраструктуры Entity Framework (добавление в контекст + сохранение контекста) и переход на SqlBulkCopy для записи в БД может обеспечить прирост производительности в десятки, а то и сотни раз. Однако, по моему мнению, использовать связку EF+SqlBulkCopy повсеместно — явный признак того, что с архитектурой вашего приложения что-то не так. Рассмотренный в статье подход следует рассматривать как простое средство для ускорения производительности в узких местах уже написанной системы, если менять архитектуру/технологию по каким-либо причинам затруднительно. Любой разработчик, использующий Entity Framework, должен знать сильные и слабые стороны этого инструмента. Успехов!
Записки IT специалиста
Типовые ошибки установки сервера 1С:Предприятие и PostgreSQL на платформе Linux.
 Связка сервера 1С:Предприятие и PostgreSQL вторая по популярности среди установок 1С и самое используемое решение на платформе Linux. В отличии внедрений на базе Windows и MSSQL, где трудно сделать так, чтобы не заработало, внедрения на базе Linux таят множество подводных камней для неопытного администратора. Часто бывает так, что вроде бы все сделано правильно, но ошибка следует за ошибкой. Сегодня мы рассмотрим самые типовые из них.
Связка сервера 1С:Предприятие и PostgreSQL вторая по популярности среди установок 1С и самое используемое решение на платформе Linux. В отличии внедрений на базе Windows и MSSQL, где трудно сделать так, чтобы не заработало, внедрения на базе Linux таят множество подводных камней для неопытного администратора. Часто бывает так, что вроде бы все сделано правильно, но ошибка следует за ошибкой. Сегодня мы рассмотрим самые типовые из них.
Общая информация
Перед тем, как начинать искать ошибки установки и, вообще, приступать к внедрению серверной версии 1С:Предприятия было бы неплохо освежить представление как это работает:
В небольших внедрениях сервер 1С и сервер СУБД обычно совмещают на одном физическом сервере, что немного сужает круг возможных ошибок. В нашем случае будет рассматриваться ситуация, когда сервера разнесены по разным машинам. В нашей тестовой лаборатории мы развернули следующую схему:
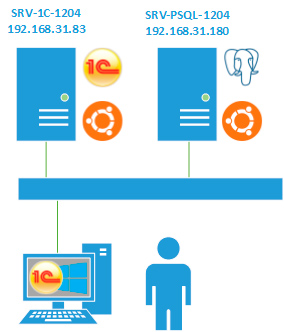
В нашем распоряжении имеются два сервера под управлением Ubuntu 12.04 x64, на одном из них установлен сервер 1С:Предприятие версии 8.3, на другом PostgreSQL 9.04 от Ethersoft, а также клиент под управлением Windows. Напоминаем, что клиент работает только с сервером 1С, который, в свою очередь, формирует необходимые запросы к серверу СУБД. Никаких запросов от клиента к серверу управления базами данных не происходит.
Сервер баз данных не обнаружен
ВАЖНО: пользователь «postgres» не прошёл проверку подлинности (Ident)
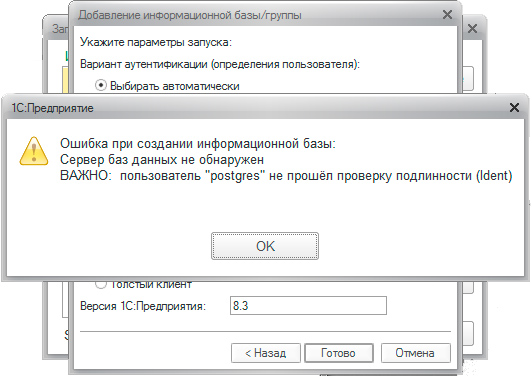
Данная ошибка возникает при разнесении серверов по разным ПК из-за неправильно настроеной проверки подлинности в локальной сети. Для устранения откройте /var/lib/pgsql/data/pg_hba. conf, найдите строку:
и приведите ее к виду:
Сервер баз данных не обнаружен
could not translate host name «NAME» to address: Temporary failure in name resolution
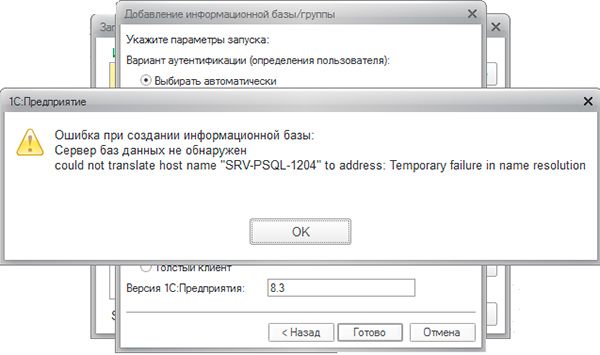
На первый взгляд ошибка понятна: клиент не может разрешить имя сервера СУБД, типичная ошибка для небольших сетей, где отсутствует локальный DNS-сервер. В качестве решения добавляют запись в файл hosts на клиенте, что не дает никакого результата.
А теперь вспоминаем, о чем было сказано несколько раньше. Клиентом сервера СУБД является сервер 1С, но никак не клиентский ПК, следовательно запись нужно добавлять на сервере 1С:Предприятие в файл /etc/hosts на платформе Linux или в C:\Windows\System32\drivers\etc\hosts на платформе Windows.
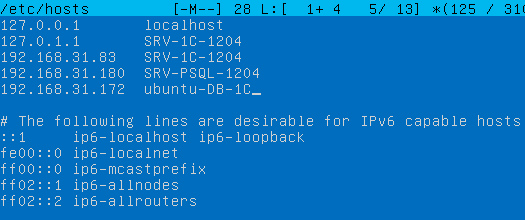
Аналогичная ошибка будет возникать, если вы забыли добавить запись типа A для сервера СУБД на локальном DNS-сервере.
Ошибка при выполнении операции с информационной базой
server_addr=NAME descr=11001(0x00002AF9): Этот хост неизвестен.
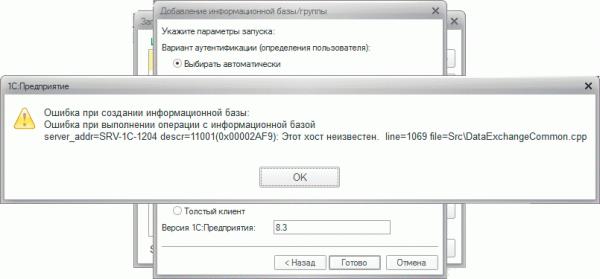
Как и прошлая, эта ошибка связана с неправильным разрешением клиентом имени сервера. На этот раз именно клиентским ПК. В качестве решения добавляем в файл /etc/hosts на платформе Linux или в C:\Windows\System32\drivers\etc\hosts на платформе Windows запись вида:
где указываете адрес и имя вашего сервера 1С:Предприятия. В случае использования локального DNS следует добавить A-запись для сервера 1С.
Ошибка СУБД: DATABASE не пригоден для использования
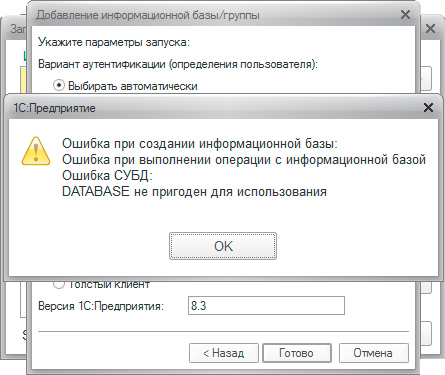
Гораздо более серьезная ошибка, которая говорит о том, что вы установили несовместимую с 1С:Предприятие версию PostgreSQL или допустили грубые ошибки при установке, например не установили все необходимые зависимости, в частности библиотеку libICU.
Если вы имеете достаточный опыт администрирования Linux систем, то можете попробовать доустановить необходимые библиотеки и заново инициализировать кластер СУБД. В противном случае PostgreSQL лучше переустановить, не забыв удалить содержимое папки /var/lib/pgsql.
Также данная ошибка может возникать при использовании сборок 9.1.x и 9.2.x Postgre@Etersoft, подробности смотрите ниже.
Ошибка СУБД:
ERROR: could not load library «/usr/lib/x86_64-linux-gnu/postgresql/fasttrun. so»
Ошибка СУБД
ERROR: type «mvarchar» does not exist at character 31
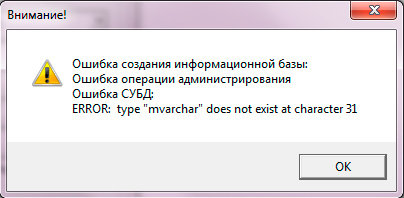
Возникает если база данных была создана без помощи системы 1С:Предприятия. Помните, для работы с 1С базы данных следует создавать только с использованием инструментов платформы 1С: через консоль Администрирование серверов 1С Предприятия
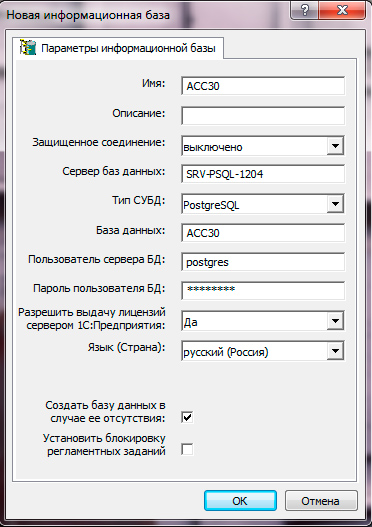
или через средство запуска 1С.
Сервер баз данных не обнаружен
ВАЖНО: пользователь «postgres» не прошёл проверку подлинности (по паролю)

Очень простая ошибка. Неправильно указан пароль суперпользователя СУБД postgres. Вариантов решения два: вспомнить пароль или изменить его. Во втором случае вам нужно будет изменить пароль в свойствах всех существующих информационных баз через оснастку Администрирование серверов 1С Предприятия.
Сервер баз данных не обнаружен
FATAL: database «NAME» does not exist
Как исправить ошибку при генерации RSA ключа для ЕГАИС?
При генерации RSA ключа (транспортного ключа) в личном кабинете ЕГАИС алкоголь могут возникать ошибки. Разобраться в этих ошибках непросто специалисту, не говоря уже о рядовом пользователе.
Попробуем разобрать типовые ошибки, которые возникают при генерации транспортных RSA ключей ЕГАИС.
Почему возникает ошибка при генерации ключа ЕГАИС?
В основном ошибки при генерации связаны с некорректными настройками компьютера.
Общие рекомендации для успешной генерации транспортного RSA ключа ЕГАИС
Для успешной генерации транспортных ключей на сайте ЕГАИС необходимо соблюсти некоторые требования и рекомендации:
Ошибка при генерации RSA ключа «Выберете устройство чтения смарт карт. «
Если при генерации ключа ЕГАИС вместо окна запроса пин-кода Вы увидели окно «Выберете устройство чтения смарт карт» или «Обнаружена смарт-карта, но она не может использоваться для текущей операции. » или «Смарт-карта не может выполнить запрошенную операцию либо операция требует другой смарт-карты», значит нужно скорректировать настройки компьютера.

Такая ошибка возникает из-за того, что настройки вашего компьютера не позволяют сформировать ключи, необходимые для работы УТМ ЕГАИС.
Если Вы используете носитель Рутокен ЭЦП, то вам необходимо сделать следующее:


Пробуйте сгенерировать транспортный ключ ЕГАИС еще раз.
В крайне редких случаях, если генерация ключа не проходит, помогает утилита восстановления работоспособности Рутокен (позволяет правильно определить драйвера носителя в системе).
Все должно получиться!
Ошибка в методе createCertificateRequest Error: CKR_PNI_INCORRECT
В этой ошибке прямым текстом, правда по иностранному, написано, что неверно введен пин-код.

Проверьте правильность ввода пин-кодов. Если на вашем носителе установлен пин-код по умолчанию. и Вы его не помните, то напоминаем:
Если не подходят стандартные пин-коды и пин-код, который установили Вы, то скорее всего носитель заблокировался. Для разблокировки носителя обратитесь к тому, у кого получали ключи, должны помочь.
Ошибка в методе createCertificateRequest Error: CKR_ATTRIBUTE_TYPE_INVALID
Такая ошибка была нами зафиксирована при использовании ключа JaCarta SE.

Для исправления ошибки необходимо инициализировать раздел PKI на носителе. Для этого откройте Единый клиент JaCarta желательно включить интерфейс Администратора (снизу слева кнопка «Переключиться в режим администрирования»). Перейдите вверху во вкладку PKI и нажмите «Инициализировать». При запросе пин-кода введите пин-код Администратора 00000000, пин-код Пользователя 11111111.
После успешной инициализации попробуйте снова сгенерировать транспортный ключ.
Также не забывайте о том, что для нормальной работы вашего защищенного носителя для ЕГАИС должен быть установлен свежий драйвер ключа!
Решения самых популярных проблем с ЕГАИС Вы можете найти в нашем Telegram канале «ЕГАИС простыми словами» (@egais_is_easy ).
https://habr. com/ru/post/251397/
https://interface31.ru/tech_it/2014/05/tipovye-oshibki-ustanovki-servera-1s-i-postgresql-na-platforme-linux. html
https://avitek. ru/info/articles/kak-ispravit-oshibku-pri-generatsii-rsa-klyucha-dlya-egais/